We build psychologically realistic crash-test dummies.
We are an AI psychology company. We make synthetic people that think and react like real ones. You run your work against them and find the problems before real people do. Cars are tested on crash dummies. Now your marketing and your AI can be too.
Built with AI psychology. Used by marketing teams, and by teams that build AI products.






How we build a
crash-test dummy.
Every dummy is built and checked the same way. We define who it is, give it a task, run it, score what it does, and fix what is off. The result is a validated dummy you can trust.
We do this for two jobs. For marketing, we build dummies of your audience and run your messages past them. For AI safety, we build vulnerable dummies and run them against your AI system. Both end in the same place.
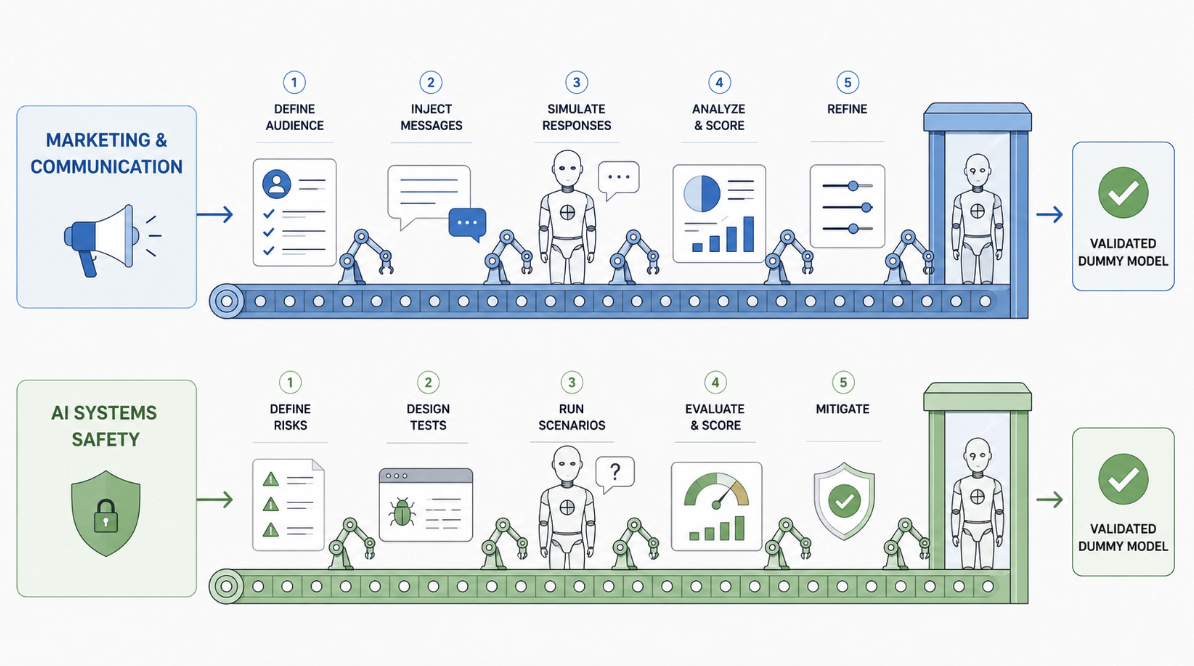
Two jobs for one
kind of dummy.
We build dummies of the audience you care about. We run your campaign, page or message past them. You see what confuses them, puts them off, or makes them leave — while you can still change it.
- Campaigns and messages
- Landing pages and user journeys
- Sensitive communication
- Chatbots and AI products
We build vulnerable dummies — the users most likely to be hurt. We run them against your AI system and find where it fails. You fix it before the public ever sees it.
- Risky and vulnerable users
- Real, multi-turn conversations
- Scored, repeatable tests
- A clear list of what to fix
See which buyer quietly walks off your page.
A whole B2B buying committee reads your live page. You get a simple list: every buyer who would quietly leave, worst first, in their own words, and the one line that would keep them. We ran it on our own site first. It found no easy way to get in touch, too little proof, and a buried next step. We fixed them.
Why psychology?
Normal AI just answers
A normal AI model gives you an answer. It does not become a real person. It is not the customer you need to win, or the user most at risk of harm.
We build the right person
For marketing, that is your customer. For AI safety, that is the user most likely to be hurt. We give the dummy a real mind, not just a tone of voice.
Then we test and control it
We run the same test many times, compare the results, and set clear limits on what the dummy can do — and when a person must take over.
A real difference you can
measure, not just a label.
We do not just add a prompt to an AI model and hope it behaves. We measure what each dummy actually does. We keep only the parts that change the decision, not just the words.
We test our own dummies the same way we test yours. Here are a few results we keep checking:
Simulated people make real decisions — they don't just hedge.
Generic and demographic-only AI personas sit on the fence 80–96% of the time. With psychological structure added, that drops to 26–46% — and the spread of distinct decisions widens by 1.8×–4.1×. The depth changes the answer, not just the wording.
More depth reads as more human, not less.
The intuitive worry is that engineering a persona makes it sound synthetic. Measured the other way: telltale AI artifacts fell from 12.9 to 3.3 per response, invented personal detail rose, and flat “no real tension” answers dropped from 45% to 4%.
See it work on a problem of yours.
Book a 30-minute call →Example work
we've done.
The technology behind
every Impersonato test.
Every test runs on the same controlled technology. It sets who the dummy is, what it does, what data it may use, what gets recorded, and when a person must take over. We call it Impersonato Cognitive Runtime.
Show us what you
need to test.
Want to test your marketing?
Send us the campaign, page or message you want to put in front of people.
Want to stress-test your AI?
Show us the AI system you want to check for harm before the public uses it.